


LLaVA = Large Language and Vision Assistant
이미지를 보고 자연어로 대화할 수 있는 멀티모달 AI
MLX = Machine Learning X
Apple의 머신러닝 프레임워크
LLaVA 모델을 다운받아서
Apple Silicon 최적화를 살짝해서
Python Flask 웹 인터페이스를 붙였습니다.
설치방법+소스는 댓글 링크 참고하세요.
바이브코딩으로 세팅해서 세밀한 설정은 저도 잘 몰라요. 🙂
[특징]
– LLaVA 모델: 검증된 오픈소스 Vision Language Model 사용
– MLX 최적화: Apple Silicon M3에서 고성능 추론
– 멀티모달 AI: 이미지와 텍스트를 함께 이해하고 분석
– 다국어 지원: 한국어, 영어 등 다양한 언어 지원
– 다크 모드 UI: 개발자 친화적인 모던 웹 인터페이스
– 프라이버시: 모든 처리가 로컬에서 실행 (데이터 외부 전송 없음)
[성능 지표]
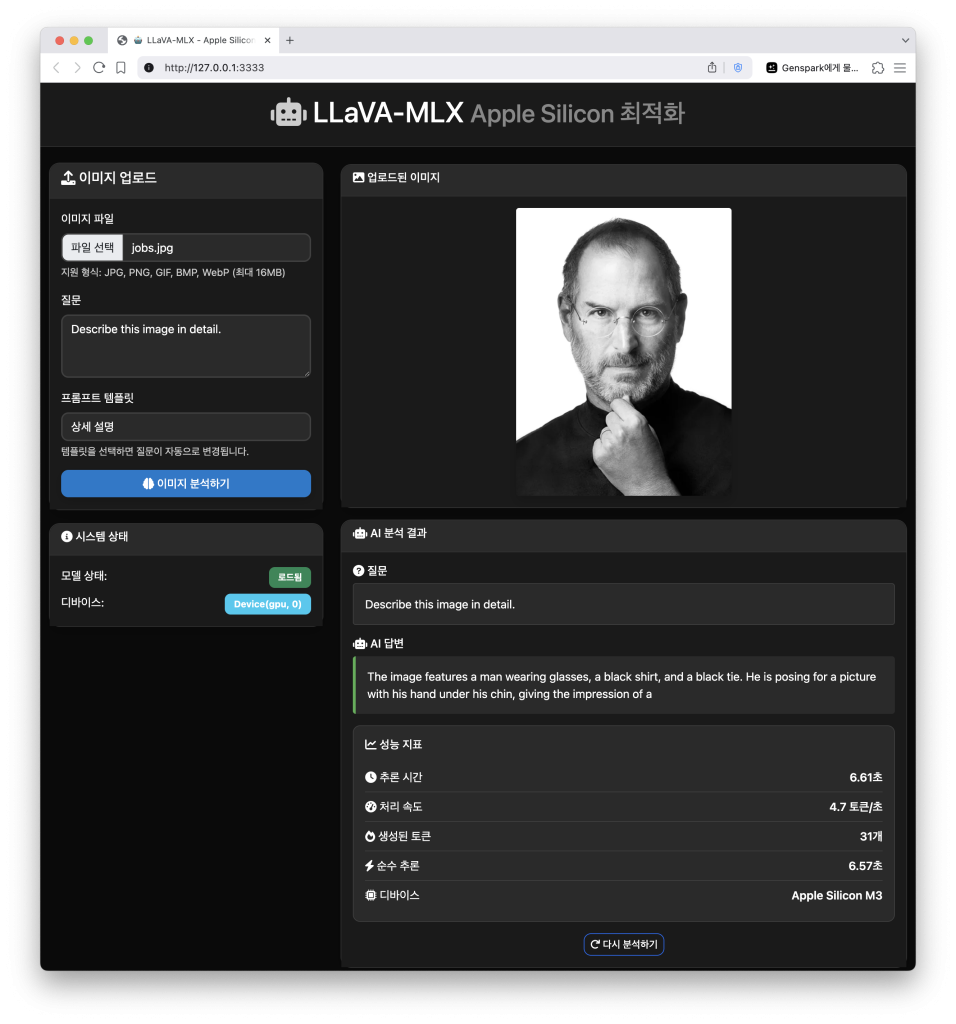
추론 시간 : 6.61초
처리 속도 : 4.7 토큰/초
생성된 토큰 : 31개
순수 추론 : 6.57초
디바이스 :Apple Silicon M3
[느낀점]
– 우와~ 맥북프로도 죽는구나
– 추론 시간 6~7초가 빠른 건지 모르겠다.
– 그냥 돈내고 API 써야겠다.